Building a Todo List Server with Model Context Protocol (MCP)
![]()
![]()
![]()
This blog post walks through creating a Todo List server using the Model Context Protocol (MCP), demonstrating how to build AI-friendly tools that integrate seamlessly with VS Code.
🔗 Source Code: The complete implementation is available on GitHub
Table of Contents
- The Evolution of AI-Assisted Development
- What is Model Context Protocol (MCP)?
- Architecture Overview
- Prerequisites
- Setting Up the Project
- Implementing the MCP Server
- VS Code Integration
- Using the Todo MCP Server
- Next Steps and Improvements
- Troubleshooting
- Resources
The Evolution of AI-Assisted Development
I have been using VS Code with GitHub Copilot for development purposes. The introduction of text-based chat, which brought GPT capabilities directly into the IDE, was revolutionary.
GitHub Copilot and the Local Tools Gap
GitHub Copilot has revolutionized how developers write code by providing intelligent code suggestions and completions. While it excels at understanding code context and generating relevant snippets, there has been a notable gap in its ability to interact with local development tools, intranet KBs, and execute actions in the development environment. This limitation means that while Copilot can suggest code, it cannot directly help with tasks like running commands, managing files, or interacting with local services.
Agent Mode: Bridging the Gap
The introduction of Agent Mode in GitHub Copilot represents a significant step forward in AI-assisted development. It enables Copilot to:
- Execute terminal commands
- Modify files directly
- Interact with the VS Code environment
- Handle project-specific tasks
This advancement transformed Copilot from a passive code suggestion tool into an active development partner that can help manage your entire development workflow. Here are some powerful capabilities and example interactions:
1. Build and Test Automation
Trigger Maven builds with specific profiles:
"Run mvn clean install with the 'production' profile for my project"
Execute JUnit test suites:
"Execute all JUnit tests in the UserServiceTest class"
Run code quality tools:
"Run ESLint on all JavaScript files in the src directory"
"Start a local Sonar analysis with coverage and security scan"
2. Documentation and Release Management
Generate release documentation:
"Generate release notes for changes between tag v1.2.0 and v1.3.0"
Technical documentation:
"Create a technical design document for the authentication service"
"Update the API documentation in Confluence for the new endpoints"
3. Project Management Integration
JIRA ticket management:
"Create a JIRA ticket for the memory leak bug we found in the login service"
"Convert all TODO comments in AuthService.java to JIRA tickets"
Sprint management:
"Update the status of PROJ-123 to 'In Review' and add a comment with the PR link"
"Show me all JIRA tickets assigned to me that are blocking the current sprint"
4. Cross-Repository Operations
Multi-repo analysis:
"Check if the latest changes in the API repo are compatible with our client library"
"Run integration tests across both the frontend and backend repositories"
While these capabilities demonstrate the power of Agent Mode, they highlight a crucial challenge: the need for external API integrations. Each of these tasks requires:
- Authentication with external services (JIRA, Confluence, Sonar)
- Managing different API versions and endpoints
- Handling various authentication methods
- Maintaining connection states and sessions
- Coordinating operations across multiple systems
This complexity creates significant overhead for developers who need to:
- Implement and maintain integration code for each service
- Handle authentication and authorization
- Manage API versioning and changes
- Deal with different response formats and error handling
MCP: The New Standard for AI Tool Integration
Model Context Protocol (MCP) emerges as the next evolution in this space, providing a standardized way for AI models to interact with development tools and services. Unlike traditional approaches where AI assistants are limited to suggesting code, MCP enables:
-
Direct Tool Integration
- AI models can directly invoke local tools
- Real-time interaction with development environment
- Standardized communication protocol
-
Extensible Architecture
- Custom tool definitions
- Plugin-based system
- Easy integration with existing services
-
Development Environment Awareness
- Context-aware assistance
- Access to local resources
- Real-time feedback loop
What is Model Context Protocol (MCP)?
Model Context Protocol (MCP) is a specification that enables AI models to interact with external tools and services in a standardized way. It defines how tools can expose their functionality through a structured interface that AI models can understand and use.
Key benefits of MCP that I have personally benefited from:
- Standardized tool definitions with JSON Schema
- Real-time interaction capabilities
- Session management
- Built-in VS Code integration
More about MCP Architecture Documentation
How MCP Tools Work
Each MCP tool follows a standardized structure:
{
name: "toolName",
description: "What the tool does",
parameters: {
// JSON Schema definition of inputs
},
returns: {
// JSON Schema definition of outputs
}
}
When an AI model wants to use a tool:
- It sends a request with the tool name and parameters
- The MCP server validates the request
- The tool executes with the provided parameters
- Results are returned in a standardized format
This structured approach ensures:
- Consistent tool behavior
- Type safety throughout the system
- Easy tool discovery and documentation
- Predictable error handling
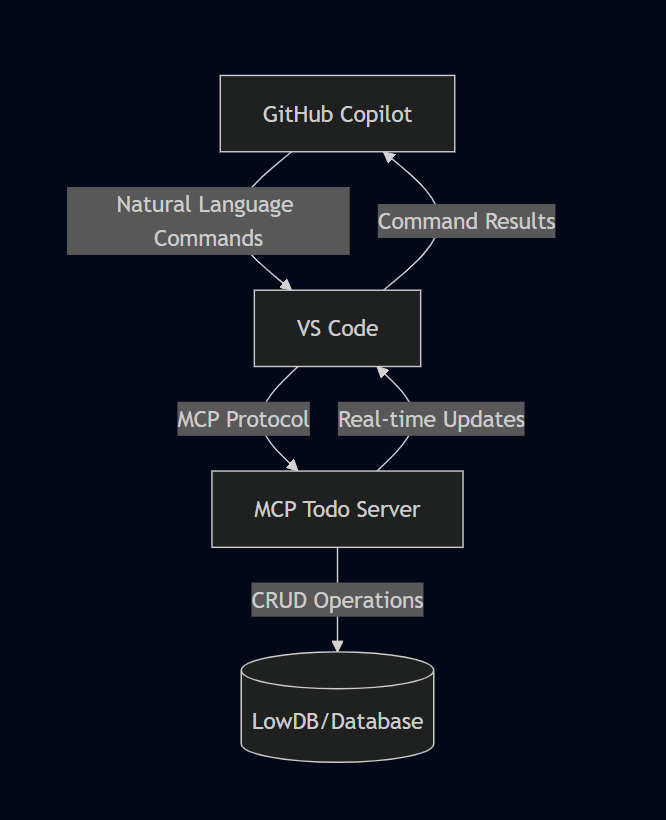
Architecture Overview
Here’s how the different components interact in our MCP Todo implementation:
graph TD
A[GitHub Copilot] -->|Natural Language Commands| B[VS Code]
B -->|MCP Protocol| C[MCP Todo Server]
C -->|CRUD Operations| D[(LowDB/Database)]
C -->|Real-time Updates| B
B -->|Command Results| A
Prerequisites
To follow along, you’ll need:
- Node.js (v22 or higher)
- VS Code
- Basic understanding of Express.js
- npm or yarn package manager
Setting Up the Project
- First, create a new project and initialize npm:
mkdir mcp-todo-server
cd mcp-todo-server
npm init -y
- Install required dependencies:
npm install @modelcontextprotocol/sdk express lowdb zod
For this demonstration, we’re using lowdb to manage tasks in a JSON file without actual integration with an external system. In a production environment, the lowdb functions can be replaced with actual JIRA CRUD API calls for end-to-end implementation.
- Create the basic directory structure:
mcp-todo-server/
├── src/
│ ├── config/
│ ├── tools/
│ ├── utils/
│ └── server.js
└── package.json
Implementing the MCP Server
1. Basic Server Setup
We started with a basic Express server that implements the MCP protocol. The server uses StreamableHTTP for real-time communication and session management.
Key components in server.js:
- Express server setup
- MCP SDK integration
- StreamableHTTP transport configuration
- Session management for maintaining tool state
2. Database Configuration
We used lowdb, a lightweight JSON database, to persist our todos. The database configuration in config/db.js handles:
- JSON file storage
- Basic CRUD operations
- Data persistence between server restarts
3. Implementing Todo Tools
We implemented four main tools for managing todos:
-
createTodo
- Creates new todo items
- Validates input using Zod schema
- Returns the created todo with a unique ID
-
listTodos
- Lists all todos or filters by completion status
- Formats output for easy reading
- Supports real-time updates
-
updateTodo
- Updates todo completion status
- Validates input parameters
- Returns updated todo information
-
deleteTodo
- Removes todos by ID
- Provides completion confirmation
- Handles error cases gracefully
VS Code Integration
To enable VS Code to use our MCP server, follow these steps:
- Enable Agent mode in VS Code. Click on the drop down just before the model listing and select agent from it.

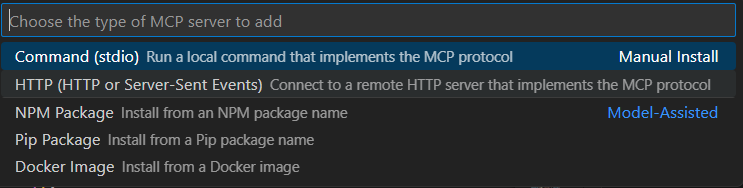
- Then click on the Gear icon next to the speaker icon in the above image and select “Add more tools” then select “Add MCP Server”

- Then select HTTP or Server-Sent Events and provide the URL based on the server we created. In this case, it’s http://localhost:3000. Then select a name for the server.


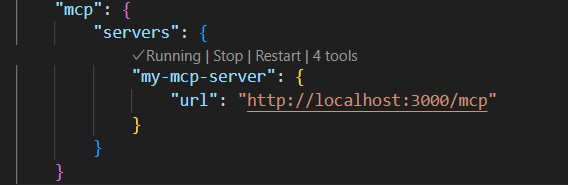
- Alternatively you can Press
Ctrl+Shift+P(Windows/Linux) orCmd+Shift+P(Mac) to open the Command Palette. Type “Open Settings (JSON)” and select it and add the following configuration:
{
"mcp": {
"servers": {
"my-mcp-server": {
"url": "http://localhost:3000/mcp"
}
}
}
}
You can use the 4th step to verify if the server is added correctly after the first 3 steps are done. The User Settings option has Start, Stop, and Restart options. This step helped me identify if there are any issues with the MCP tools server effectively.
-
Reload VS Code to apply the changes or use the Start, Stop, Restart options in the settings.json as shown above.
-
After successful addition of the MCP server, you should see the tools listed when you click the gear icon in the Copilot chat window.
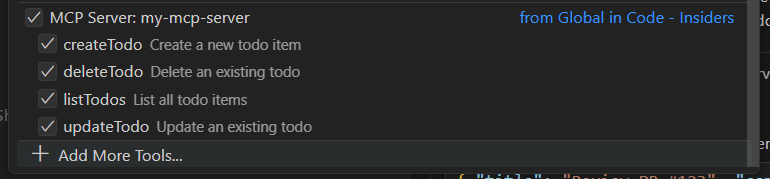
Using the Todo MCP Server
Here are some example prompts you can use in VS Code with GitHub Copilot to interact with the todo server. Each example includes a screenshot of the actual interaction:
-
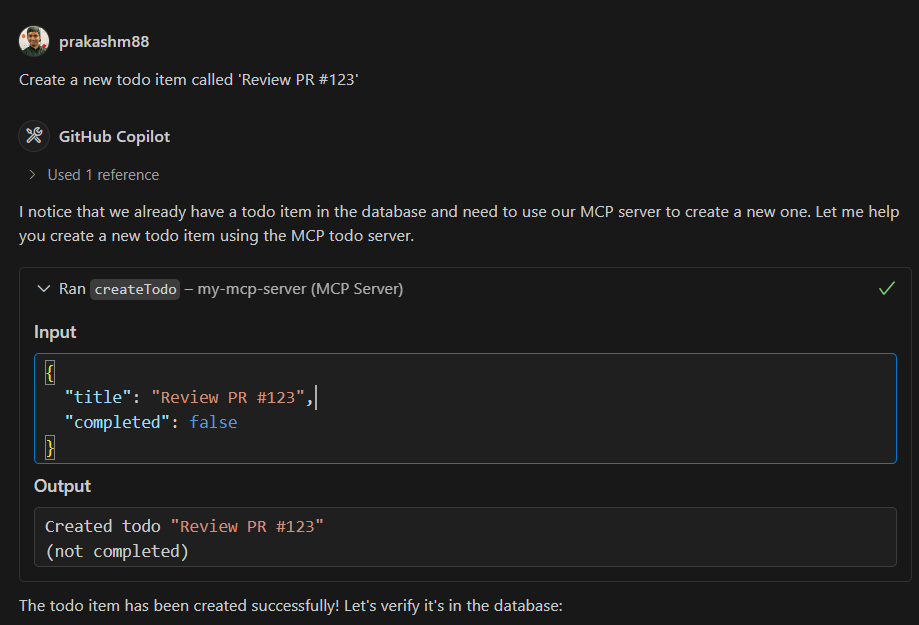
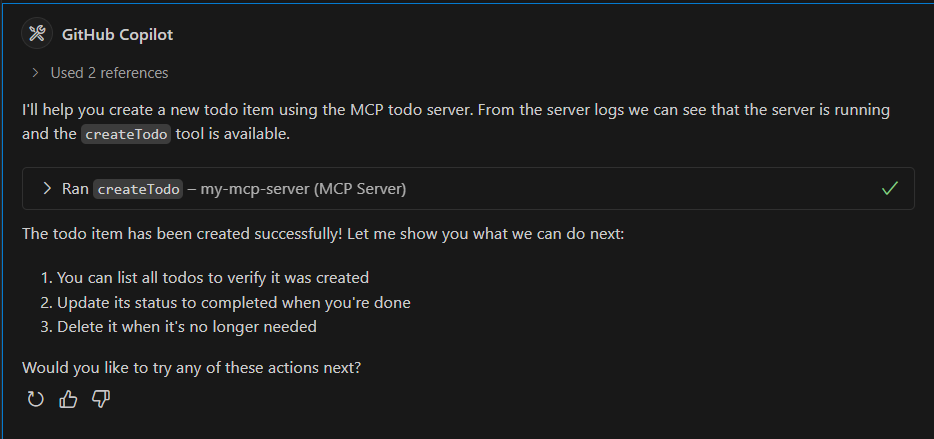
Creating a Todo
Prompt: "Create a new todo item called 'Review PR #123'" Response: Successfully created todo "Review PR #123"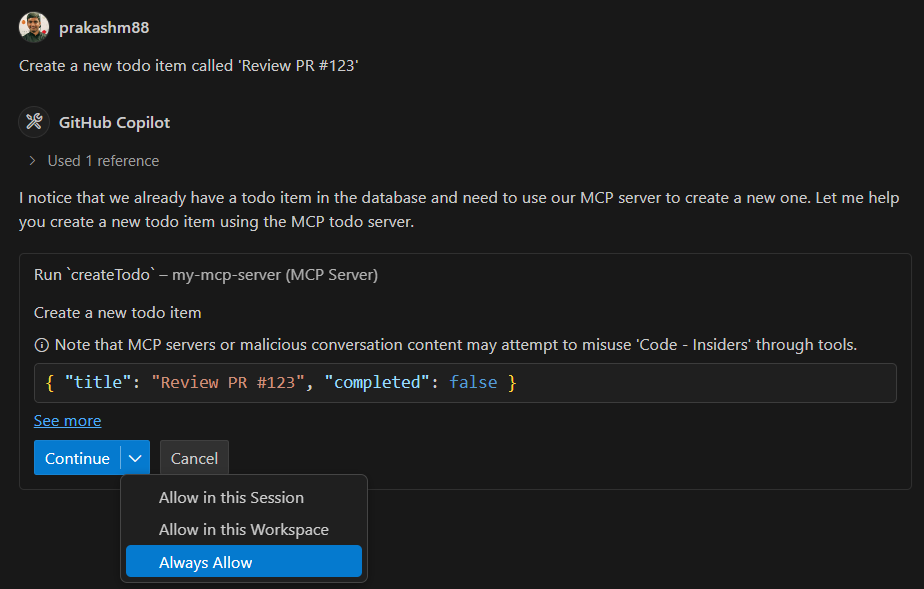
-
Listing Todos
Prompt: "Show me all my todos" Response: Here are your todos: - Review PR #123 (Not completed) - Update documentation (Completed) - Setup test environment (Not completed)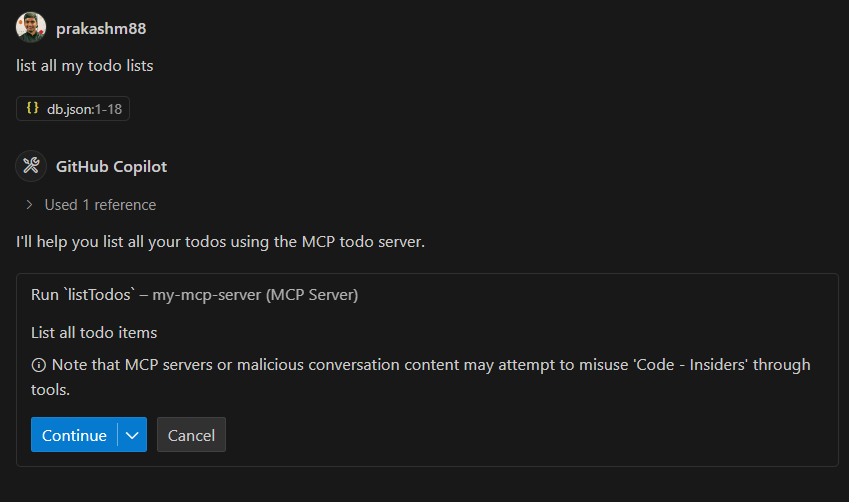
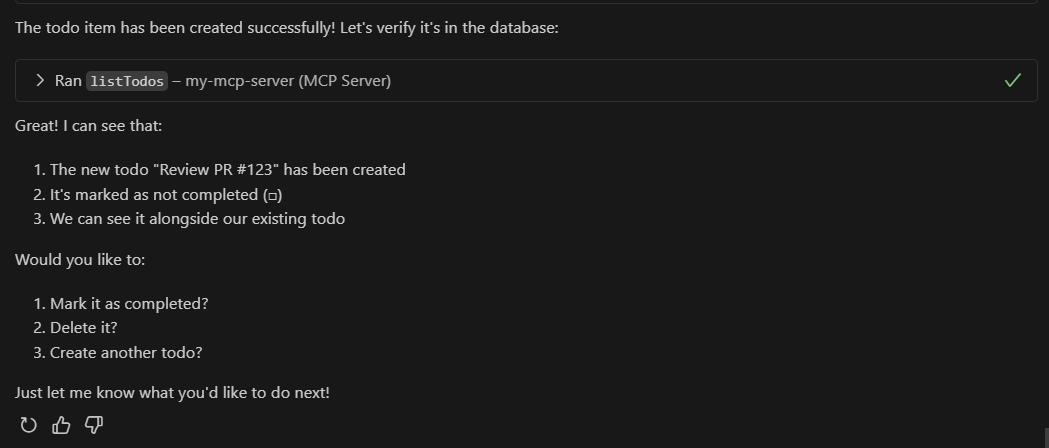
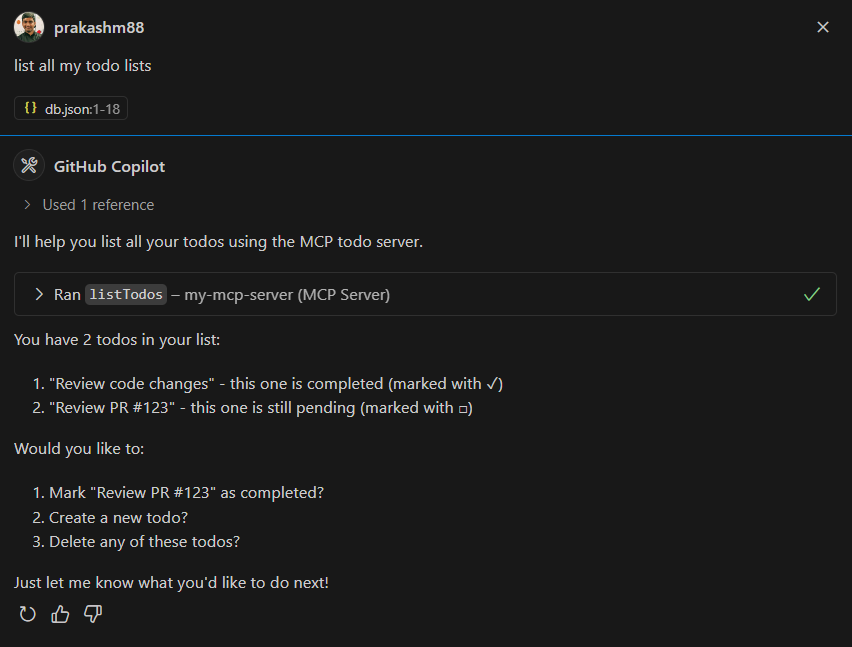
-
Updating a Todo
Prompt: "Mark the todo about PR review as completed" Response: Updated "Review PR #123" to completed -
Deleting a Todo
Prompt: "Delete the todo about documentation" Response: Successfully deleted "Update documentation" -
Filtering Todos
Prompt: "Show me only completed todos" Response: Completed todos: - Review PR #123
Next Steps and Improvements
Potential enhancements for the project:
-
Authentication
- Add user authentication
- Implement role-based access
-
Advanced Features
- Due dates for todos
- Categories/tags
- Priority levels
-
Performance
- Caching
- Database optimization
- Rate limiting
-
Testing
- Unit tests
- Integration tests
- Load testing
Troubleshooting
Common Issues and Solutions
-
Server Connection Issues
- Verify the server is running on port 3000
- Check VS Code settings for correct server URL
- Ensure no firewall blocking the connection
-
Tool Registration Problems
Error: Tool 'createTodo' not found Solution: Check if server is properly initializing tools in server.js -
Schema Validation Errors
- Ensure todo items match the required schema
- Check Zod validation rules in tool implementations
- Verify JSON payload format
-
Real-time Updates Not Working
- Confirm SSE (Server-Sent Events) connection is established
- Check browser console for connection errors
- Verify StreamableHTTP transport configuration
Source Code Reference
Key implementation files:
- Server setup:
src/server.js - Tool implementations:
- Database configuration:
src/config/db.js
Conclusion
We’ve successfully built a fully functional MCP-compatible Todo server that:
- Implements CRUD operations
- Maintains persistent storage
- Provides real-time updates
- Integrates seamlessly with VS Code
This implementation serves as a great starting point for building more complex MCP tools and understanding how AI models can interact with custom tools through the Model Context Protocol.
Resources
mcp-todo-server
This project is a simple MCP server that manages a todo list using the Model Context Protocol TypeScript SDK. It provides a RESTful API for creating, updating, and deleting todo items.
Project Structure
mcp-todo-server
├── src
│ ├── resources
│ │ └── todos.js
│ ├── tools
│ │ ├── createTodo.js
│ │ ├── updateTodo.js
│ │ └── deleteTodo.js
│ ├── config
│ │ └── db.js
│ ├── utils
│ │ └── sessionManager.js
│ └── server.js
├── db.json
├── package.json
├── .gitignore
└── README.md
Installation
-
Clone the repository:
git clone https://github.com/prakashm88/mcp-todo-server.git cd mcp-todo-server -
Install the dependencies:
npm install
Usage
To start the server, run:
npm start
The server will listen on port 3000.
API Endpoints
- POST /mcp: Handles client-to-server communication for creating and managing todos.
- GET /mcp: Retrieves server-to-client notifications.
- DELETE /mcp: Terminates a session.
Database
The project uses lowdb to manage the todo items, stored in db.json.
Contributing
Contributions are welcome! Here’s how you can help:
- Fork the repository
- Create a feature branch:
git checkout -b feature/my-new-feature - Commit your changes:
git commit -am 'Add new feature' - Push to the branch:
git push origin feature/my-new-feature - Submit a pull request
You can also:
- Report bugs by creating issues
- Suggest improvements through discussions
- Help improve documentation
Please read our Contributing Guidelines for more details.